|
竞技宝官网app·还不如人类五岁小孩难度为零的视觉测试GPT-4o却挑战失败了近期的研究探讨了GPT-4o、Claude 3.5 Sonnet等视觉语言模型(VLM)在图像理解方面的能力。尽管这些先进的模型在处理人类行为识别、物品识别等复杂场景时表现出色,但在一系列基础视觉任务上的表现却差强人意。研究通过7项涉及基本几何形状的任务测试发现,这些VLM的平均准确率仅有56.2%,显示出它们更像是基于线索推测而非真正“观看”。相关论文以“Vision language models are blind”为标题,已在arXiv网站发布。
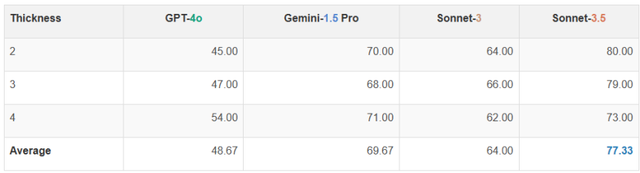
研究中,即便是辨认线条交叉点数量、圆圈是否重叠这类对人类来说极为直观的任务,VLM的完成度也并不理想。比如,在识别交叉线数量时,最高准确率不过77.33%,且随着线条间距缩小,其性能下滑。同样,判断圆圈重叠时,没有模型能达到完美,且圆圈间距减小时,错误率增加,表明VLM在捕捉细微差异上存在困难。
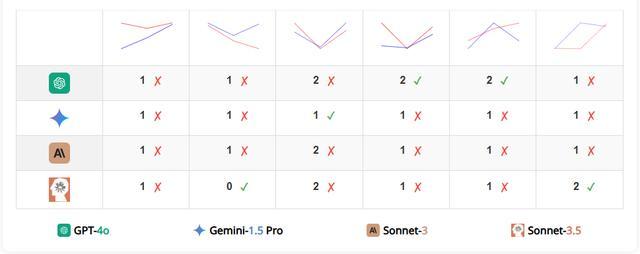
此外,VLM在识别被圈定字母、重叠形状数量等任务上的表现亦暴露出不足。它们虽然能够正确拼写被圈字母所在的单词,却难以准确指出被圈的究竟是哪个字母,有时还会错误地生成不存在的字符。在计数重叠或嵌套的几何图形时,模型往往依赖训练数据中的常见模式(如奥运五环标志)进行猜测,导致准确性受限。
值得注意的是,VLM在识别网格的行列数以及计算单色路径数量的任务上也面临挑战,仅在加入辅助信息(如网格内填充文本)后,其表现才有所提升,但仍远未达到完美。这暗示着VLM在无文本辅助的纯粹视觉推理上存在局限。 竞技宝官网app |